이재욱 교수 연구진, 메모리 효율적인 Any-Precision LLM 기술로 세계 선도

- 하나의 n-비트 대규모 언어모델(LLM)에 여러 정밀도의 모델(예: n, n-1, ..., 4, 3-비트)을 중첩하는 알고리즘 개발
- 상황에 따라 동적으로 선택된 정밀도에 맞춰 LLM을 효율적으로 실행하는 소프트웨어 엔진 개발
- 제한된 메모리에서 서로 다른 정확도-속도 상충관계를 갖는 멀티 모델들을 지원하여, LLM 기반 어플리케이션의 사용자 경험을 개선
- ICML 2024 Oral Presentation (최상위 1.5%) 논문 선정
이재욱 교수 연구진이 LLM 기반 어플리케이션의 사용자 경험을 획기적으로 향상시킬 수 있는 핵심기술을 개발하였다.
LLM을 운용할 때, 빠른 응답이 필요한 쿼리와 응답 시간이 크게 중요하지 않은 쿼리가 뒤섞여 들어올 수 있다. 예를 들어, 챗봇과 같은 대화형 응용 프로그램에서는 매우 빠른 응답이 필요하지만, 문서 분석과 같은 작업에서는 느린 응답도 허용되는 경우가 있다. 또한, 시스템의 부하에 따라 응답의 품질과 지연시간의 상충관계(tradeoff)를 조정하고자 할 수도 있다. 이렇게 다양한 응답 시간 요구사항을 가진 쿼리들을 효과적으로 처리하는 것은 사용자 경험을 개선하는 데 매우 중요하다. 이를 위해서는 여러 크기의 모델을 준비하고, 각 쿼리에 맞는 모델을 동적으로 선택해 사용하는 것이 유리하다. 그러나, 이러한 방법은 여러 버전의 모델을 저장하기 위한 메모리 사용량을 증가시킨다.
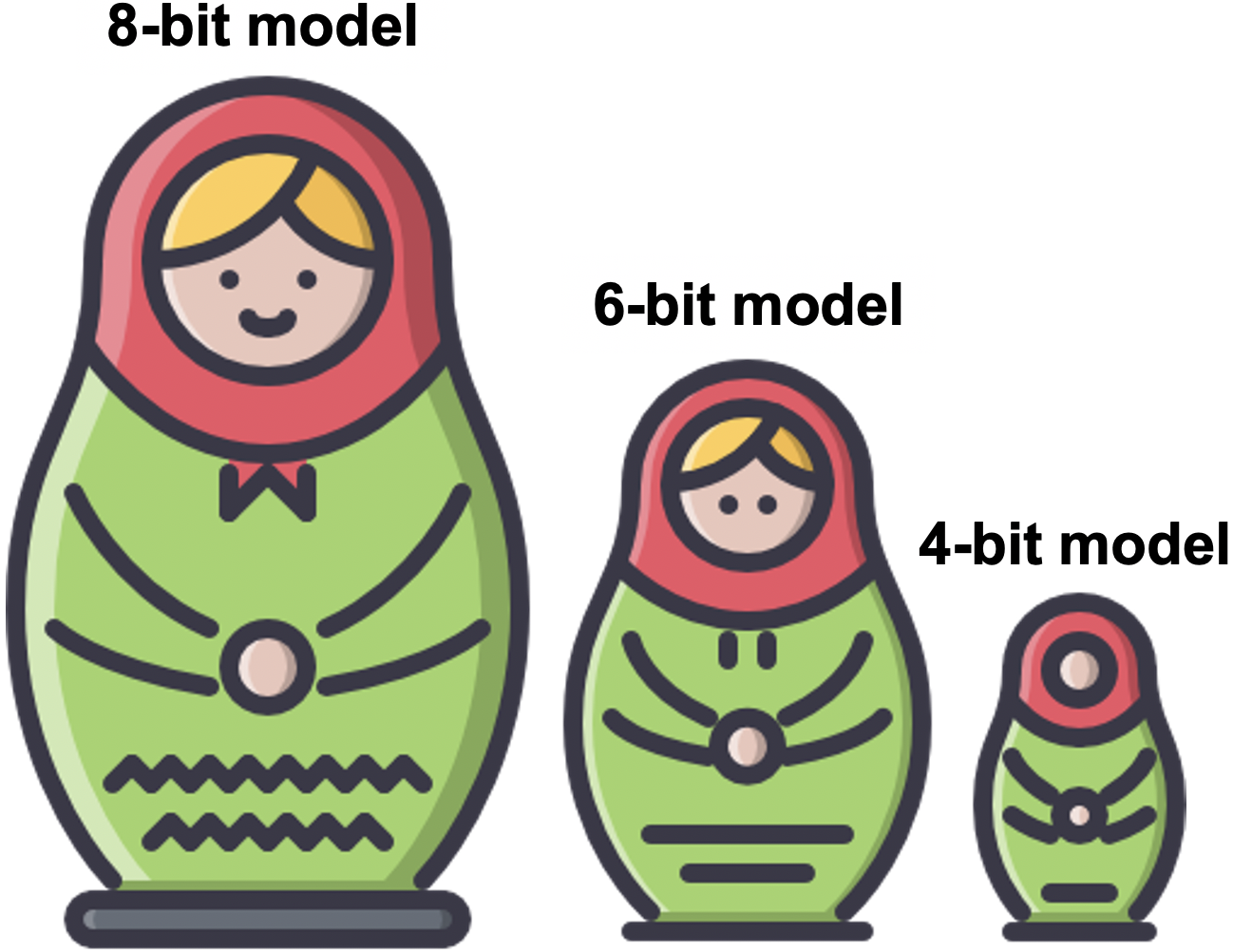
이 문제를 해결하기 위해 이재욱 교수 연구팀은 LLM에 특화된 임의 정밀도 양자화(any-precision quantization) 기술을 세계 최초로 개발했다. 제안한 기법은 마치 러시아의 마트료시카(Matryoshka) 인형처럼, n비트 모델에 그보다 낮은 정밀도를 가진 n-1, n-2, … 비트 모델을 중첩(overlay)하여 적은 메모리로 다양한 정밀도의 모델 운용을 가능하게 한다. 이 기술을 활용하면, n비트로 양자화된 모델 하나만 메모리에 저장해 두고, n비트 모델의 각 매개변수에서 최상위 비트의 일부만 사용하여 낮은 정밀도의 모델도 효과적으로 지원할 수 있다. 연구팀은 이러한 개념을 매개변수가 매우 많은 LLM에 쉽게 적용할 수 있도록, 재학습이 필요 없는 빠르고 가벼운 임의 정밀도 양자화 알고리즘을 고안했다. 또한, 이렇게 완성된 Any-Precision LLM을 효율적으로 실행할 수 있는 새로운 소프트웨어 엔진을 개발하여, 세계 최고 수준의 모델 성능 및 추론 속도를 달성했다.
이 연구는 LLM이 다양한 어플리케이션에서 높은 수준의 사용자 경험을 제공하는 데 핵심 기술로 활용될 것으로 기대된다. 해당 논문은 오는 7월에 개최되는 머신러닝 분야 최고 권위의 학회인 ICML 2024에서 발표될 예정이다. 특히 전체 제출 논문 중 최상위 1.5%만 선정되는 구두 발표(Oral Presentation) 세션에 채택되어 그 우수성을 인정받았다.
"Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs", Yeonhong Park, Jake Hyun, SangLyul Cho, Bonggeun Sim, Jae W. Lee, ICML 2024.