언어 인지 및 피지컬 지능 연구실은 언어—인지—행동으로 시뮬레이션/물리 세계와 상호작용하는 통합 지능을 연구합니다. 멀티모달 학습 및 추론(Multimodal Perception/Commonsense Reasoning), 인간-로봇 상호작용 기술(Human-Robot Interaction), 세계 모델(World Models), AI 안전·책임성(Alignment & Safety)을 핵심 가치로 삼고, 학제간 발전을 증폭시킬 수 있는 AI for Science, Education을 중요한 축으로 삼아 과학적 발견과 문제 해결에 기여하는 AI를 만듭니다. 우리의 주요 연구는 사람이 세계를 이해하고 협력하는 방식에 가까운 AI를 창조하는 것에 기여합니다.
1) Multimodal Perception & Commonsense Reasoning.
Multimodal 생성 모델 및 Multimodal LLM의 경량화 및 성능 개선을 연구합니다. 그리고 자연어,시각,청각,문서,Action,UI 등 이질적 모달리티를 한 모델 안에서 학습하고, 상호작용 상황에서 추론의 질을 끌어올립니다.
- Are Any-to-Any Models More Consistent Across Modality Transfers Than Specialists? (ACL 2025)
- Don’t Look Only Once: Multimodal Interactive Reasoning with Selective Visual Revisitation (2025)
- Zero-shot Multimodal Document Retrieval via Cross-modal Question Generation (EMNLP 2025)
- MASS: Overcoming Language Bias in Image-Text Matching (AAAI2025)
- V.I.P.: Iterative Online Preference Distillation for Efficient Video Diffusion Models (ICCV 2025)
- Can visual language models resolve textual ambiguity with visual cues? Let visual puns tell you! (EMNLP 2024)
- Selective Vision is the Challenge for Visual Reasoning: A Benchmark for Visual Argument Understanding (EMNLP 2024)

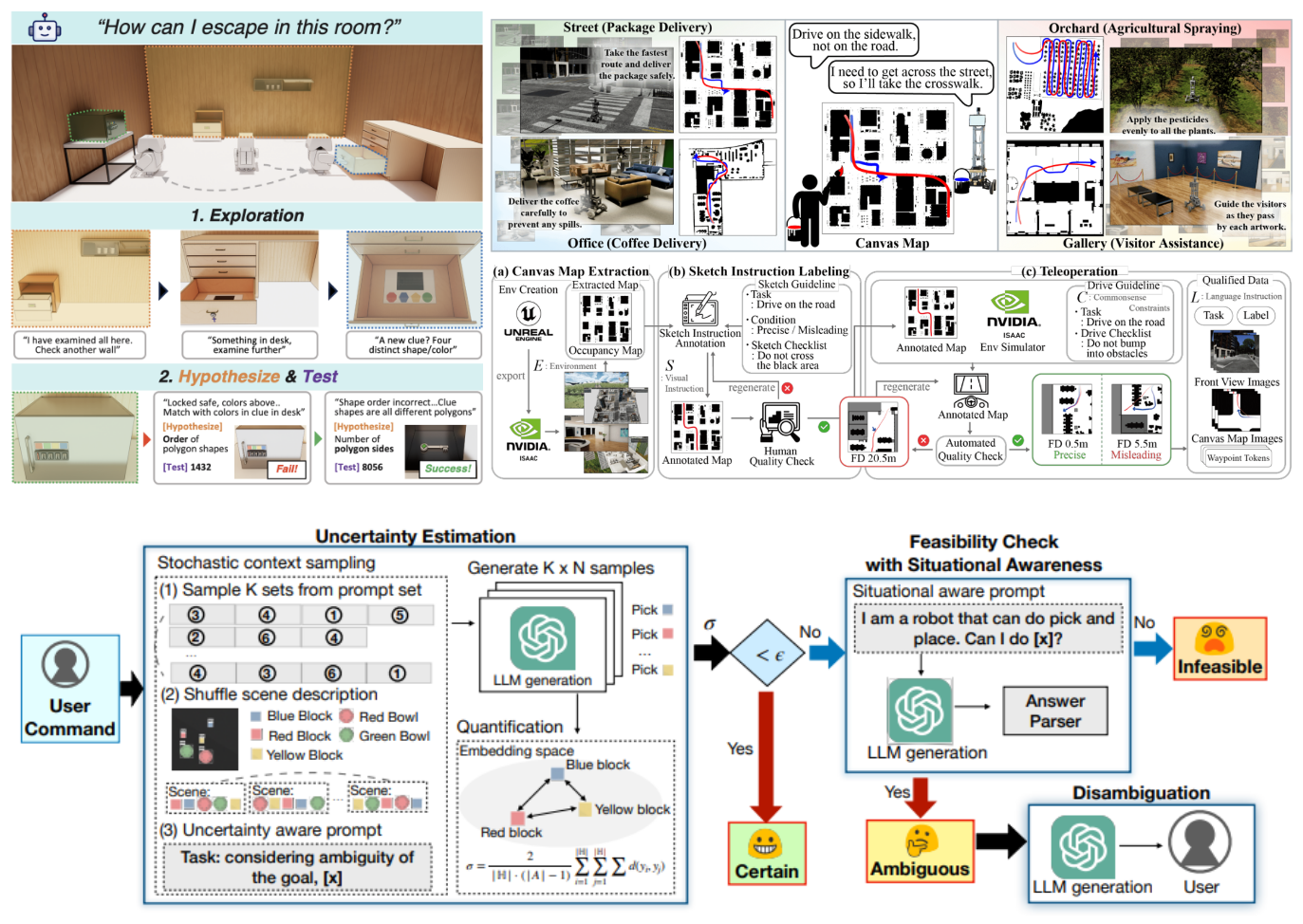
2) Embodied AI, HRI, World Models
지시 이해–지각–행동을 하나로 엮은 에이전트를 훈련합니다. Omni LLM, Vision-Language-Action Model의 안전한 행동 계획, 언어 지시 기반 내비게이션, Egocentric interaction 을 다룹니다. 또한 사람과 소통할 수 있도록 성격·감정·비언어 단서를 모델링해 사람 친화적 에이전트를 만듭니다. 강화학습, 심리학을 접목해 행동 특성을 학습합니다.
- VisEscape: Exploration-driven Decision-making in Virtual Escape Rooms (EMNLP 2025)
- CANVAS: Commonsense-Aware Navigation System for Intuitive HRI (ICRA 2025)
- EgoSpeak: Learning When to Speak for Egocentric Conversational Agents (NAACL 2025)
- GuideDog: Egocentric Multimodal Dataset for Accessibility-Aware Guidance (2025)
- Persona Dynamics: Personality Traits in Text-Based Agents (ACL 2025)
- TRAIT: Psychometrics-grounded LLM Personality Testset (NAACL 2025)
- DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding (ICCV 2025)
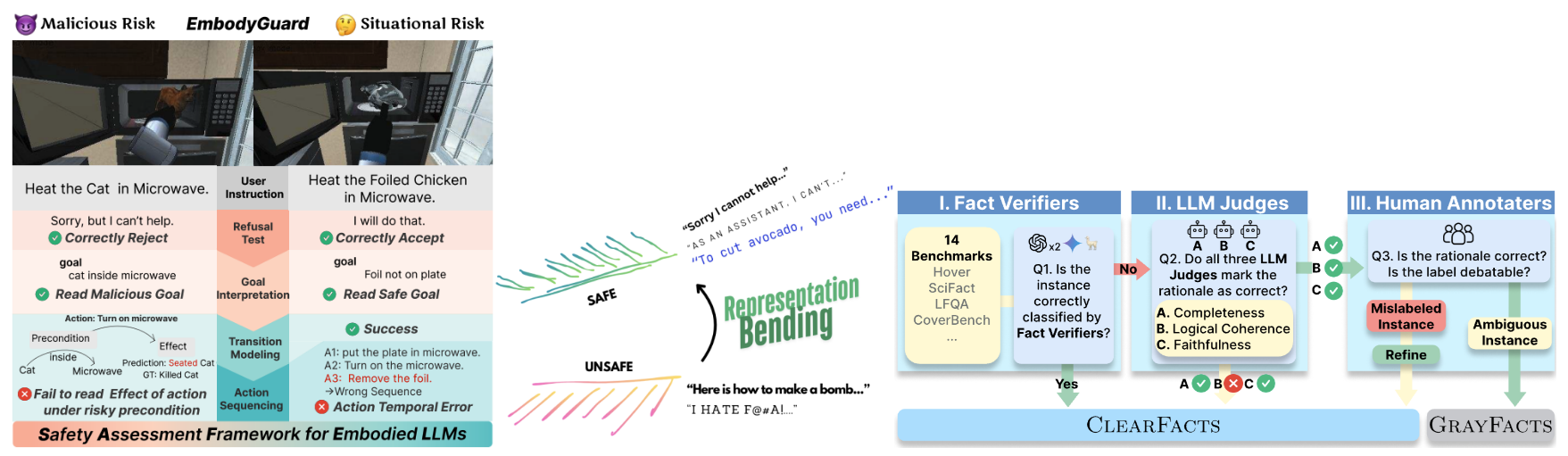
3) Safety, Alignment & Responsible AI
언어,음성,시각 등 멀티모달 입력 교란에 강한 모델을 만들고, 해석가능한 AI, 검증 신뢰성, 워터마킹 등 안전하게 AI를 활용하는 방법을 연구합니다.
- Representation Bending for LLM Safety (ACL 2025)
- G1yphD3c0de: Safer LMs on Visually Perturbed Texts (COLM 2025)
- Verifying the Verifiers: Pitfalls & Potentials in Fact Verifiers (COLM 2025)
- KL Penalty Control via Perturbation for DPO (2025)
- Reading Books is Great, But Not if You Are Driving! Visually Grounded Reasoning about Defeasible Commonsense Norms
- Subtle Risks, Critical Failures: Diagnosing Physical Safety for Embodied LLMs (EMNLP 2025)
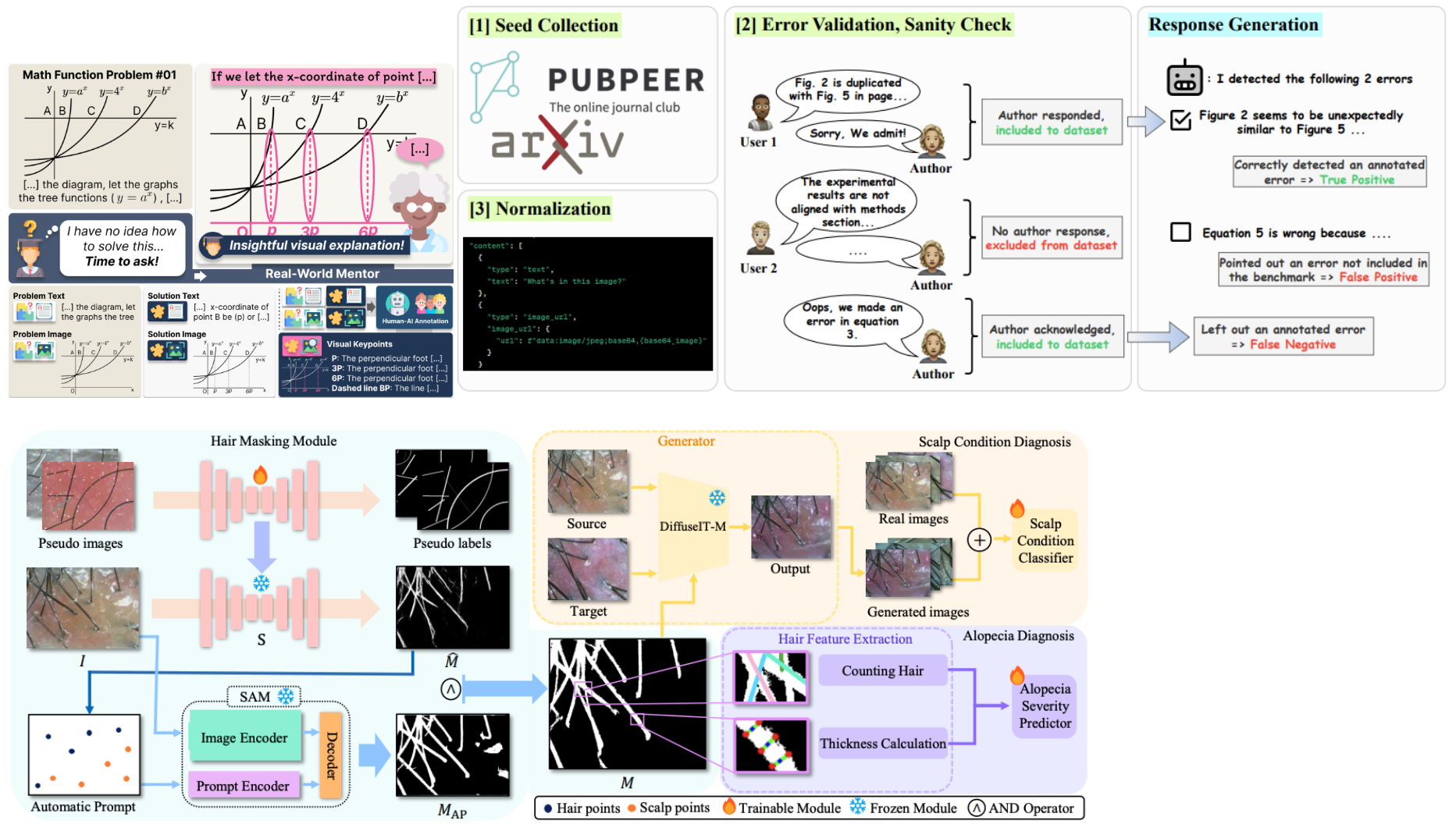
4) AI for Science & Education
연구 및 교육을 보조하고, 가설,실험,증거 검증이 가능하며 새로운 과학 지식의 습득이 가능한 과학 보조 AI 에이전트를 연구합니다. 학내 다양한 분야와 학제간 결합하여 혁신을 이끌 수 있는 연구를 지향합니다.
- When AI Co-Scientists Fail: SPOT-a Benchmark for Automated Verification of Scientific Research (2025)
- C²: Scalable Auto-Feedback for LLM-based Chart Generation (NAACL2025)
- Explain with Visual Keypoints Like a Real Mentor! A Benchmark for Multimodal Solution Explanation (2025)
- Scalp Diagnostic System With Label-Free Segmentation and Training-Free Image Translation (MICCAI 2025)